
- SĐT liên hệ: (+84) 926 397 972 | (+84) 333 371 116
[PE2024675] Đồ Án Tốt Nghiệp - Phát Hiện Trùng Lặp Văn Bản Sử Dụng Học Máy -64%
Upload bởi: DevJava22
DevJava22
1,400,000đ
500,000đ
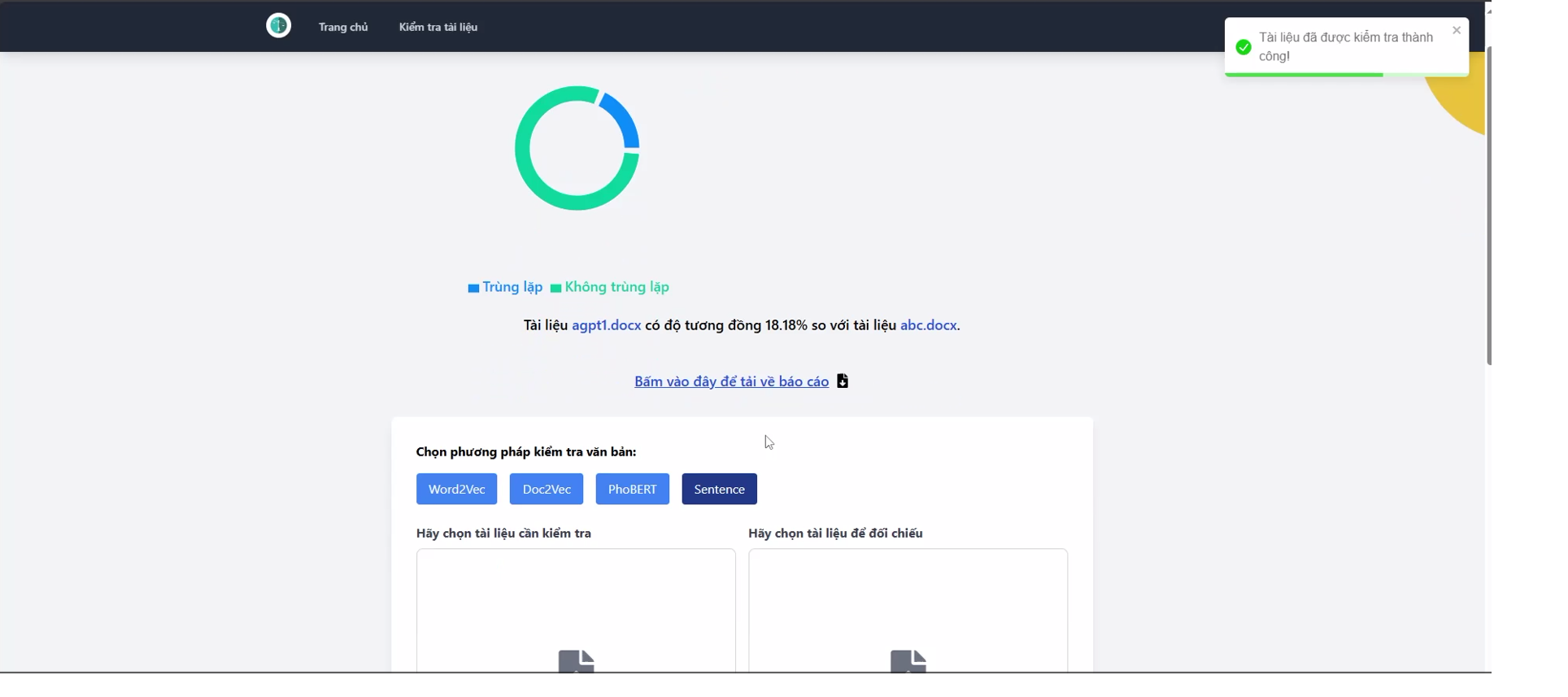
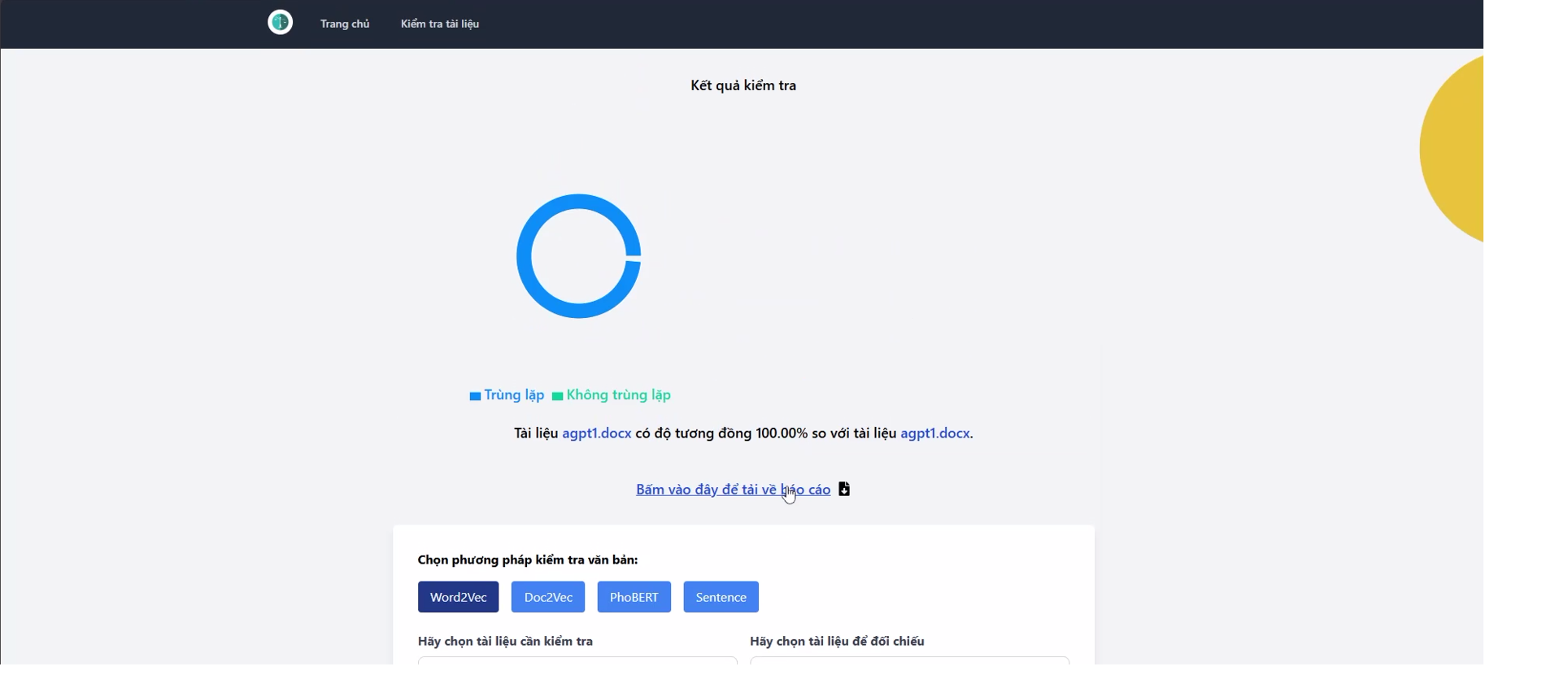
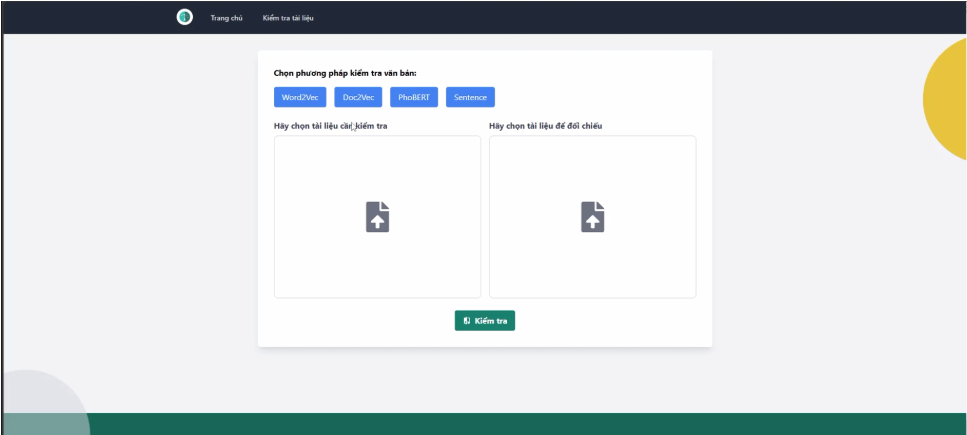
1. Xây dựng, cài đặt thử nghiệm và đánh giá mô hình phát hiện trùng lặp văn bản sử dụng học máy 2. Xây dựng module tính toán độ trùng lặp: đầu vào 2 file văn bản, đầu ra thông báo tỷ lệ trùng lặp (Từ, câu, đoạn).
Python
Source code
25/12/2024
g1.png
-
Chức năng đầy đủ và giống demo 100%
-
Hỗ trợ lắp đặt nếu cần
-
Hỗ trợ trả lời người mua sau khi tải
Bài đăng
36

Đánh giá (6)
5/5

Ngày tham gia
24/05/2024
📚 Phát hiện trùng lặp văn bản là một ứng dụng quan trọng của máy học trong việc kiểm tra đạo văn và đảm bảo tính độc quyền của nội dung. Trong video này, tôi sẽ hướng dẫn chi tiết về cách xây dựng mô hình máy học để phát hiện trùng lặp văn bản và các công nghệ được sử dụng.
1️⃣ Tổng quan về bài toán phát hiện trùng lặp văn bản
2️⃣ Phương pháp xử lý dữ liệu văn bản
3️⃣ Ứng dụng máy học trong phát hiện trùng lặp: Sử dụng thuật toán Cosine Similarity và các mô hình máy học như Naive Bayes, SVM hoặc Logistic Regression.
5️⃣ Thử nghiệm và đánh giá kết quả trên các tập dữ liệu mẫu.
6️⃣ Gợi ý mở rộng phát triển cho các dự án thực tế.
💡 Phù hợp với:
✅ Những người muốn tìm hiểu về xử lý ngôn ngữ tự nhiên (NLP).
🚀 Mục tiêu của dự án:
Phát hiện nhanh chóng các tài liệu trùng lặp với độ chính xác cao.
Tích hợp các mô hình học máy vào hệ thống quản lý nội dung (CMS).
Giảm trùng lặp nội dung và đảm bảo tính minh bạch.
Cài đặt python, nodejs
backend: sử dụng python với framework fastapi:
- Sử dụng pip install -r requirements.txt để cài đặt các thư viện
- uvicorn main:app --reload để khởi chạy dự án
- Frontend: sử dụng reactts:
- npm i để cài đặt các thư viện
- npm start để khởi chạy dự án
Xuất sắc
Rất tốt
Tốt
Trung Bình
Cần cải thiện

Bài đăng cùng danh mục:
 PE2024676
PE2024676
 PE2025115
PE2025115
 PE2025116
PE2025116
Bài đăng mới nhất:
 PE2025206
PE2025206
 giaodichcode.contact
giaodichcode.contact PE2025205
PE2025205
 PE2025204
PE2025204
Full Code Nền tảng học trực tuyến LMS (NextJS + NodeJS + MongoDB + Chatbot AI)
499,999đ
999,999đ
-50%
 PE2025203
PE2025203
 votruong
votruong PE2025202
PE2025202
 thong.phan109
thong.phan109 PE2025201
PE2025201
 PE2025200
PE2025200
5,123
+
THÀNH VIÊN
40,587
+
LƯỢT TẢI
9,421
+
LƯỢT ĐĂNG
92,346
+
KHÁCH HÀNG TƯƠNG TÁC
- Đơn vị kinh doanh: Công ty TNHH Đầu Tư Công Nghệ TechByte
- Địa chỉ: Số nhà 10, dãy H, Khu tập thể Công an Đa Sỹ, Phường Kiến Hưng, Quận Hà Đông, Thành phố Hà Nội, Việt Nam
- Phone: (+84) 926 397 972
- Phone: (+84) 333 371 116
- Email: [email protected]
- Website: https://hotrodoan.vn/
- Giấy phép kinh doanh: Số 0110801570 bởi Sở Kế hoạch và Đầu tư Hà Nội.

Copyrights © 2023
Nội dung đã được bảo vệ bản quyền
